In autumn 2022, I took CS330: Deep Multi-Task and Meta Learning at Stanford. My partner and I delved into the foundations of transfer learning by attempting to build a network or technique that can inform which transfer learning starter to use, given a fine-tuning dataset. Our model, which we called ChoiceNet, had the following signature:
- Input: two-tuple
- Pre-trained model’s weights or training dataset
- Fine-tuning dataset
- Output: test-set accuracy after fine-tuning
In other words, if you know your fine-tuning dataset and can pick from 2+ pre-trained models, is there a heuristic or network to choose the frozen base model for fine-tuning?
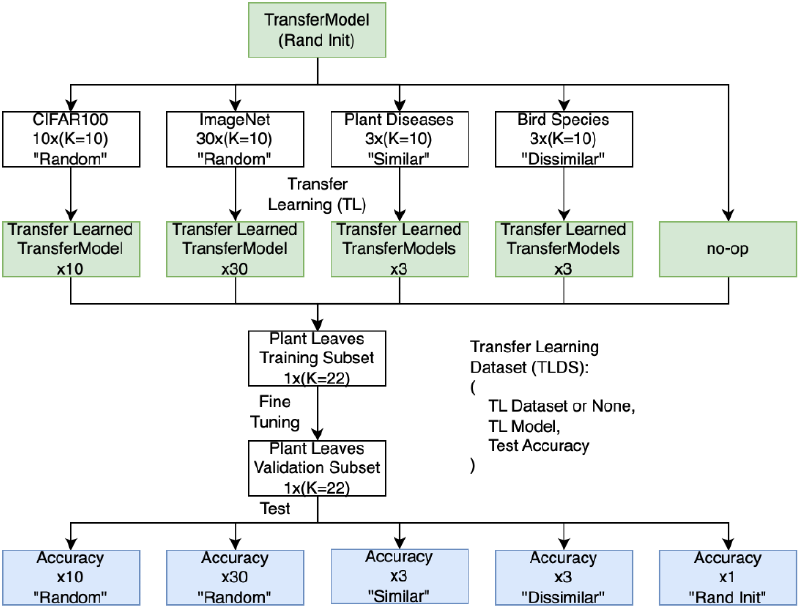
Transfer Learning Dataset#
To begin experimentation, fabricated a dataset mapping:
- X: (transfer dataset or pre-trained weights, fine-tuning dataset)
- Y: test-set accuracy
We used a very simple CNN as our core model being transfer learned ("TransferModel"),
so we could quickly pre-train and export weights.
Our fine-tuning dataset was of plant leaves.
We created four categories of datapoints:
- Constant and similar to fine-tuning dataset
(via TensorFlow
plant_villagedataset) - Constant and dissimilar to fine-tuning dataset (via bird species dataset)
- Random 10-class subsets of CIFAR-100 or ImageNet
- Empty dataset (no pre-training = random initialization), as an experimental control
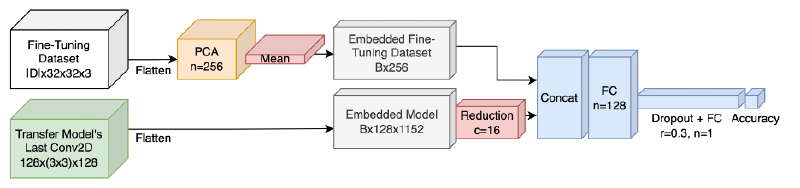
Architecture Versions#
ChoiceNet v1 took the following actions:
- Embedding the pre-trained model: flattened weights from
the
TransferModel’s last 2-D convolution - Embedding the fine-tuning dataset: applied 256-element principle component analysis (PCA) for bulk reduction, then averaged along examples
- Combining both embeddings: (1) LoRA-similar reduction of embedded pre-trained model, (2) concatenate both embeddings, and (3) pass into head of two fully-connected layers with dropout
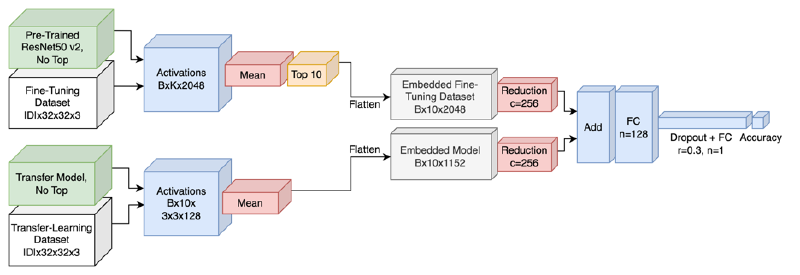
ChoiceNet v2 fixed a few misgivings:
- Fine-tuning dataset’s average along examples removed too much information
- Class-specifics were entirely ignored
- Transfer learning dataset was unused
To fix these issues, ChoiceNet v2 does the following:
- Embedding the pre-trained model and transfer dataset: use activations (not weights) from last 2-D conv, and average activations per-class
- Embedding the fine-tuning dataset:
use activations from a pre-trained
ResNet50v2, average along classes, and keep the 10 classes with the highest average absolute value activation - Combining both embeddings: (1) LoRA-similar reduction to both embeddings, (2) sum the embeddings (instead of concatenation), and (3) pass through same fully-connected head as ChoiceNet v1
Findings#
A disclaimer is this project’s core question was incredibly broad. Given just one quarter we only used one fine-tuning dataset and one domain (supervised image classification).
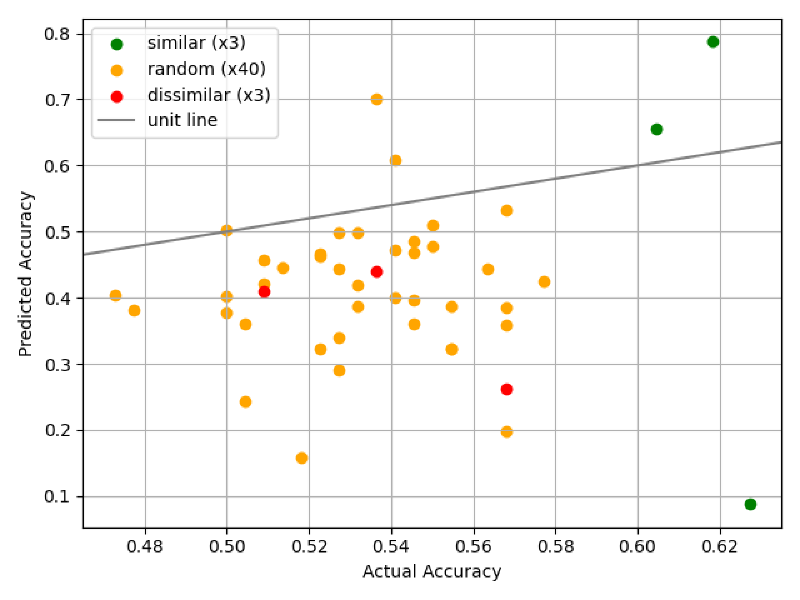
- ChoiceNet v2 decreases test-time MSE loss by 80%, and underestimates final accuracy vastly less than ChoiceNet v1
- We created several unsupervised mathematical techniques (not detailed in this article) using distribution distance, raw pixel values distributions, or average class correlation to predict test set performance
