Overview#
In late January 2025, DeepSeek released R1, illuminating a pathway to the world: reinforcement learning with verifiable rewards (RLVR) can elicit and improve reasoning capability.
FutureHouse’s Head of Science Andrew immediately became excited about applying RLVR in the chemistry domain. We began a sprint scoped for two weeks that went on to take five months, materializing into:
- An open-weight 24B model called
ether01. - Open-source reward functions 2 and test set.
- An acceptance to NeurIPS 2025’s main track.
- arXiv preprint: Training a Scientific Reasoning Model for Chemistry
- A feature on the front page of nature.com.
- A cool overview video and research blog post.
There were two aspects not open sourced:
- RL training code: written via
torch+torch.distributed, our code was standard GRPO code. It wasn’t open sourced due to a combination of other pressing projects, and a desire to open source code using a framework such as Nvidia’s NeMo RL. - RL training data: due to licensing issues we cannot open the dataset.
However, we open sourced question templates in
problem_prompts.py.
Late Nights#
Burned into my memory is both the excitement and the stress associated with week-long training jobs involving up to 384 H100 GPUs.
From the get-go, we had an immense exploration space. We investigated reward shaping such as soft vs. hard rewards, curriculum learning via caching success rates, data augmentations like rephrasal, rejection sampling heuristics for SFT data, different multitask pairings, and format reward strictness. Each run required specification of many hyperparameters: KL penalty or reference, completion length, base model, model size and/or quantization, attention mechanism, sampling parameters (e.g. temperature or top-K), group size + batch size + corresponding learning rate, learning rate warm-up, and more. Since our goal was multitask chemical reasoning, we often settled upon known-reasonable hypers to keep the ball rolling.
Throughout training, we constantly scrutinized outputs for signs of reward hacking. Fixing one reward hack would unlock the next level of reward hacks in a mostly iterative/sequential process. Fixes could be paired with the addition of more tasks, leaning into the hopes of a shared underlying representation. This coincided with opportunities for better engineering, such as recording entropy or reward failure modes, improving logs for future debugging, recognizing retryable failures, or simply unit testing the verifiability of train/test data.
And the world was coming out with new papers every week, such as LIMO, s1, DAPO, LLama-Nemotron, and many more.
All of our excitement was invested into LLM training, with much less attention given to ML engineering/ops. Besides Slurm for job scheduling, we had no cluster monitoring/alerting, synchronous sampling and checkpointing, no job prioritization, and limited investment into optimizations such as DeepSpeed ZeRO. Internally the term “node arrakis” was coined, because we had far more experiments to run than GPU nodes.
The solution we employed was functional but tough:
monitor training jobs all the time,
memorize the landscape of hyperparameters and job failure modes,
fend for your ideas when timelines were tight,
and believe in yourself.
Thankfully, FutureHouse began investment into
our infra stack after ether0’s success.
Expert Iteration Reinforcement Learning#
Following DeepSeek’s methodology, we trained with a warm-start of SFT then multitask reinforcement learning. We tested pure RL, but observed our model falling into nonsense babbling, and empirically observed 15-min SFT jobs surpassing days of RL training. With this knowledge we concluded our first training baselines, and began comparison with other models.
Contemporary frontier models were terrible at our tasks, with initial open-answer benchmarks of DeepSeek R1 solving below 10% of questions. We also observed tasks such as solubility edit attaining similar levels of performance to other tasks like retro synthesis in less than one fifth the training steps, which means tasks were learned at different rates. Eventually we discovered our model hill climbed much faster with a subset of tasks, and began “specialist” trainings focused on individual or a few tasks.
Separately, we observed an intriguing phenomenon appearing in long RL runs.
The reasoning would begin to contain flaws:
typos, misuse of emojis, malformatted Markdown/sentences,
and usage of up to 25 non-English languages.
We quantified the steady increase of flaws
using regexes, typos, and LLM judges.
Was this steganography, the model learning to encode information,
or the model buying itself time to complete latent logic flows?
Others witnessed this too,
as six months later an OpenAI study
documented low-quality reasoning as distinct dialect.
Non-English phrases decrease usefulness (you probably can’t read Tifinagh)
and compromise trust, so this was a problem.
We considered the flawed reasoning to be the tip of the iceberg
of weight-space shifts inside the model, some useful some not.
The question is, can one preserve the accuracy gains of RL,
while ditching whatever underpinned the low-quality reasoning?
Coming off the aviary paper, our minds were primed for iterative self-improvement techniques such as expert iteration. To resume training we could start from a model checkpoint, but an alternate approach was conceived: form an SFT dataset by (1) exporting all completions throughout training, (2) filtering out completions with incorrect answers or flawed reasoning (rejection sampling), and (3) deduplicating problems based on latest training step. The intuition was that behavioral shifts seen within high-quality correct reasoning traces distilled the model’s learnings. Actually, this “data checkpoint” approach worked surprisingly well… after SFT’ing the base model, we saw performance drop <10% from the prior RL’d model. We furthermore hypothesized one pass of SFT shifted the model less in weight space than a lengthy RL run containing many KL resets.
From this realization, we formalized a core methodology of our paper, informally nicknamed Expert Iteration Reinforcement Learning (EIRL):
- SFT from the base model to jumpstart performance,
- RL to push performance,
- Rejection sample RL completions into an improved SFT dataset.
- Repeat steps 1-3 until plateau, optionally adding more tasks each iteration.
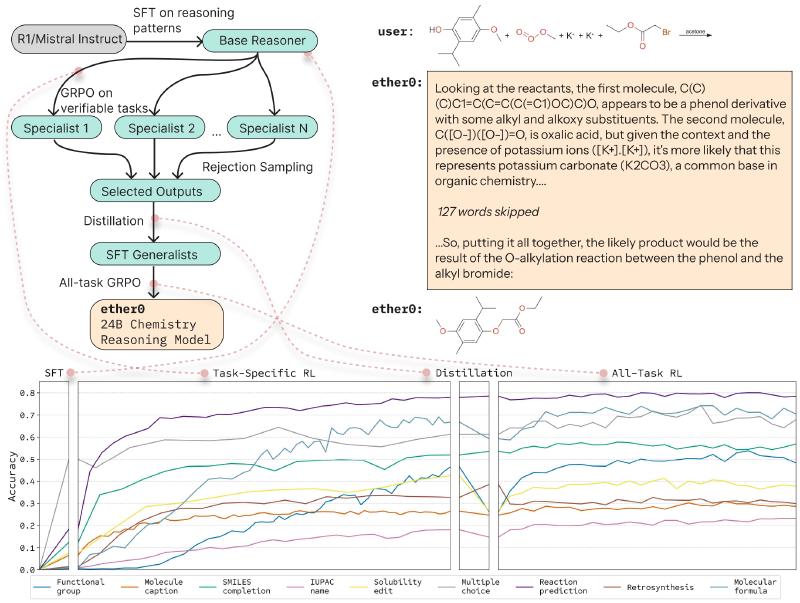
ether0 paper’s Figure 1.
We ran two iterations of EIRL:
the first made eight specialist models (training on up to three tasks),
and the second consolidating a generalist performing highly on all tasks.
The “Distillation” box in the bottom center
illustrates the slight performance loss after SFT,
which is quickly recovered during RL.EIRL showed us the long-term asset would be our SFT data, not a given model checkpoint. These synthetic traces can apply to any base model, circumvent the issue of tasks learning at different rates, and are a white box for human audits. We improved EIRL by grouping several tasks together for the first iteration, such as functional group with molecular formula. And for our final RL training run, we included all tasks at once.
Interestingly enough, an alternate version of EIRL existed in our curriculum learning technique. We stored problems the model didn’t get right or wrong 100% of the time, and re-fed these problems into future training steps, maximizing the learnable problems encountered. EIRL and this curriculum learning together suggest at some class of methods reminiscent of the movie Edge of Tomorrow 3, where throwaway runs acquire information or data that sets the stage for a speedrun final training.
Fast-forward to fall 2025,
and in the DeepSeek-V3.2-Exp technical report,
DeepSeek describes training math, coding, logic, and search specialists.
The specialists are then distilled into the final model, exactly as EIRL describes.
It’s unclear if DeepSeek was inspired by ether0’s methods,
but it is evidence that EIRL is generally applicable.
Sources#
Closing#
ether0 was a very memorable project,
here is a song embodying what kicking off some of the big runs felt like:
ether0was post trained from Mistral-Small-24B-Instruct-2501. ↩︎Andrew detailed the battles against reward hacks in his blog post building reward functions. ↩︎
A Edge of Tomorrow-inspired presentation, featuring EIRL and the custom curriculum learning, can be found on GitHub. ↩︎
